音声信号を利用した映像間同期について1
序章
当社のfvLIVEでは,複数のカメラからの映像取得,配信を行っております.
そこで課題の一つとなっているのが,カメラ間の同期問題です.現状の運用では,人材コストがある程度かかり,またある程度のfvLIVEプロダクトの知見が必要なるため,どうにかして同期の簡略化を実現したい次第です.
一方ライブで無ければ,https://vook.vc/n/593 で紹介されているようなツールを使用できますし,ライブであれば,YAMAHAさんの技術を使用しても実現できそうです.
さて,当社ではリアルタイム処理+特定の撮影機器を使わない+音声符号化後の音声信号+独自エンジンサーバー+クラウドで同期+コスト面の問題(泣)など様々な問題もあり,自動同期出来ないかについても独自に研究開発を行っています.以下,当社のfvLIVE構成です.
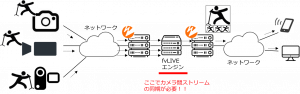 技術概要
技術概要
カメラからの映像は全て同期されていない状態で,かつネットワークの遅延揺らぎの影響からカメラ間の映像同期が保証されないのは自明です.ハイエンドカメラや業務用カメラ,ハイエンドハードウェアエンコーダを介せば,SMPTEなどのタイムコードをストリームに埋め込むことも可能であったり,特定の撮影アプリを使用すれば,H.264/AVCのSEI NAL構造を利用したタイムコードの挿入なども可能となるでしょう.しかしながら当社のfvLIVEでは,数多のお客様の状況に対応するため,「様々な機器での撮影+配信」+「マルチアングルなのに低コスト」をモットーにしています.そのため別の方法でのカメラ間映像同期の自動化を課題としています.
現在取り組んでいるのが,「ウェーブレットパケット相互相関関数を用いた合図音声信号の検出とカメラ間同期について」です.すごくざっくり言うと,
- 合図音声信号の特徴的な部分情報を予め取り出しておき,
- ライブ本番時には,その合図信号をそれぞれの複数カメラで(同時に)流して,
- クラウドサーバ上で合図音声信号の特徴情報と比較・検出し,
- その部分に該当する映像のフレームを結合させる.
というものです.ありきたりですね,ですが,他研究開発と異なることは,「特定の環境を仮定しない」+「音声信号は符号化されている」ということでしょうか.つまり「雑音入りまくり」+「人間の可聴域以外の音声信号は多く損失する」という状況での実現を目指します.
さて,まだまだ音声技術の知見は少ないですが,ウェーブレットパケットなるものを利用してみることにしました.(なぜ本技術かということは社外秘(笑)です.)
本稿の結論から言うと,同期は実現できそうです.(まだプロトタイプ作成中...)アルゴリズムの説明などの難しいことは次回以降に回して本稿では簡易実験結果だけ載せます.
簡易実験
実験概要
先ず今回の実験で使用する合図音声信号は以下のものです.
二つの方法で合図音声を挿入し,今回の方法で合図音声を検出・抽出できるかどうかを実験しました.
1.LIVE Shell Proのマイク入力をiPhoneに接続+HDMIケーブルでビデオカメラ接続し,iPhoneの中のmp3合図信号を挿入する

合図音声が挿入された瞬間ははっきりとわかりますね.しかし,変なノイズ音が乗ってしまっています.合図音声の再生が終了したあともこのノイズはずっと続きました.原因は不明です.
2.LIVE Shell Proに接続されたカメラで合図音声mp3が再生されるiPhoneを撮影することで,合図音声信号を挿入する

こちらは,カメラのマイク入力から合図音声を入れる方法であり,合図音声に対する雑音比も高いことがわかります.
上記のようにして,作り出した音声を予め作成しておいた合図音声の特徴的な部分情報と比較し,それぞれの数字を検出・抽出できるかを実験しました.その結果が以下です.
1-1:数字3の検出
→ うまく検出・抽出出来てますね.
1-2:数字2の検出
→ こちらも問題ないです.
1-3:数字1の検出
→ 問題なし
1-4:数字0の検出
→ 問題なし
2-1:数字3の検出
→ すごく聞こえづらいですが,確かに検出・抽出されていることがわかります.
2-2:数字2の検出
→ 失敗です.唯一数字2だけ検出・抽出に失敗してます.音として聞こえるのは,「鼻すすり」のような音です.数字2の子音部分の特徴と似ていたため,検出に失敗したようです.
2-3:数字1の検出
→ 問題なし
2-4:数字0の検出
→ 問題なし
考察
上記実験から,どちらの方法でも検出可能であることがわかりました.しかし,1の方法ではノイズが入ってしまいます.こちらは今後原因を調べてみます.2については検出できない場合もありました.ウェーブレットパケット解析後の係数をグラフ化も行って比較してみましたが,誤検知した「鼻すすり」と「数字2の音声」に似た特徴をしていました(グラフも含めて詳細は次回以降に記載します).
おしまいに
本稿では,まず「Gnzoはこんなことも研究開発してますよー」という概要がわかるように記載を心がけました.様々な環境での実験,様々な合図音声の使用,可聴域以外の音での実験など本来行わなければいけませんが,取り急ぎは実装から始めています.具体的な研究開発の内容は次稿に説明していく予定です.次稿 → ウェーブレットとは?ウェーブレットパケット?,相互相関関数?などをわかりやすく説明します.なるべく数式なしで.今後もよろしくお願いいたします.